















Posted By

Monolithic applications work — until they don't. As teams grow and release cycles get longer, the codebase becomes a coordination problem as much as a technical one. Python microservices change that, but only if you understand what you're actually signing up for.
This guide covers how production-grade Python microservices behave in the real world — team ownership, deployment independence, distributed failures, and data consistency trade-offs. A food delivery system (Order, Payment, Delivery) is used as the case study throughout so every concept maps to something concrete rather than staying theoretical.
Python microservices — build faster, deploy independently, fail smaller
A microservice isn't defined by how small it is — it's defined by what it owns. Each service is responsible for a specific business capability and exposes it through APIs or events.
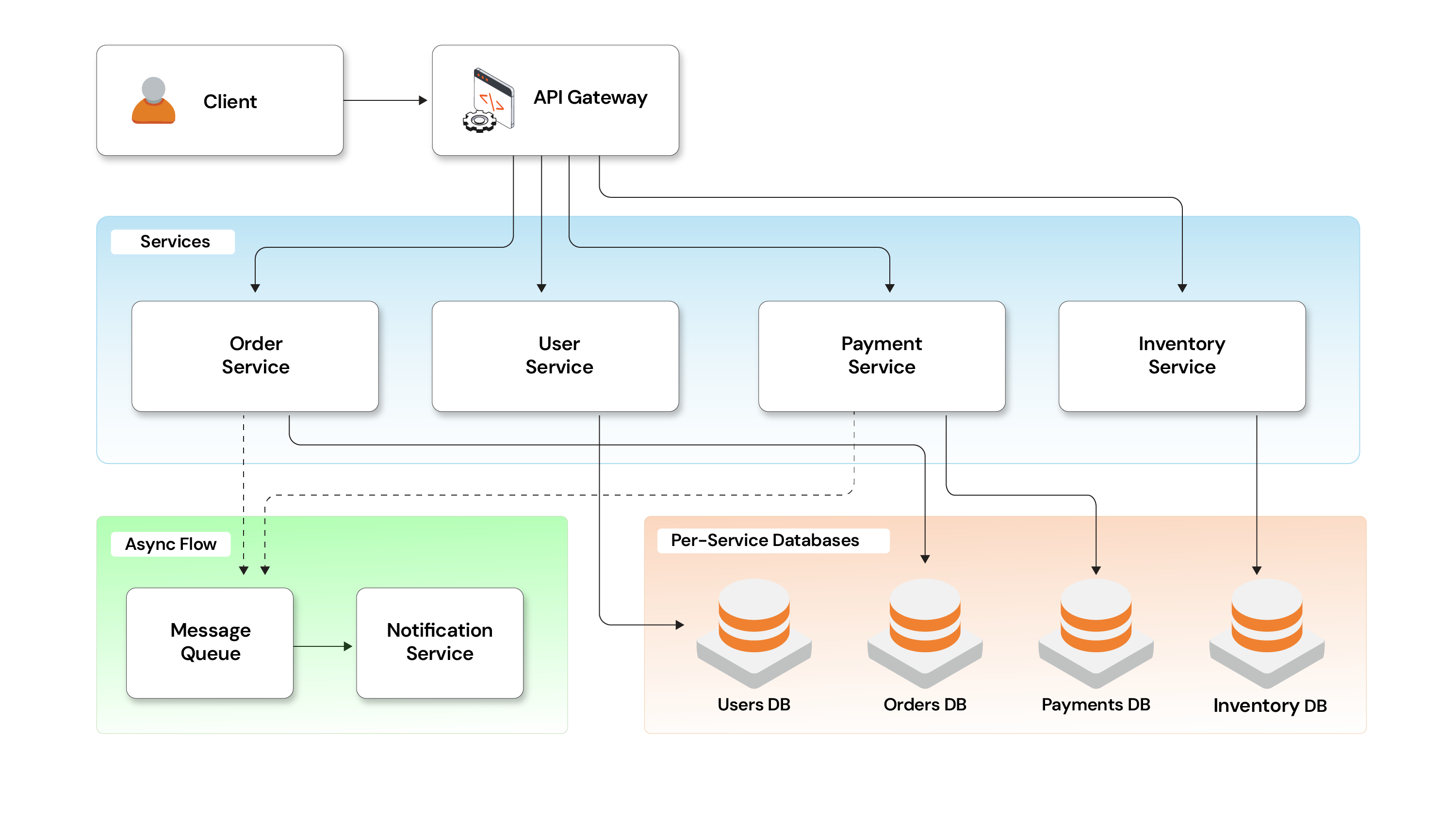
The important idea is simple: each service owns its logic, its data, and its lifecycle.
How this applies to our case study
We're building a food delivery system where placing an order triggers multiple steps:
- Order gets created
- Payment gets processed
- Delivery gets assigned
In a monolith, all of this lives in one codebase and one database. A small change in delivery logic means retesting the entire flow.
In our design, we’ve split this into:
- Order Service
- Payment Service
- Delivery Service
But the goal is not just “splitting services”. The real goal is clear ownership:
- Order Service doesn’t know how payment works
- Payment Service doesn’t care about delivery logic
- Delivery Service can evolve independently
They interact only through defined APIs/events.
What makes this work
A few key principles show up clearly in this system:
- Single responsibility — each service maps to a business function
- Independent deployment — Payment can be updated without touching others
- Own data — no shared database, each service manages its own
- Explicit communication — calls can fail, so retries and timeouts are built in
- Clear ownership — each service is responsible for its uptime and behavior
Why build Python microservices
Microservices are not better by default. They’re useful when a system starts hurting:
- Changes become risky
- Deployments slow down
- Teams start blocking each other
For example: In a monolith, changing delivery rules might require retesting the full checkout flow. Here, Delivery can change independently as long as its API stays stable.
Python is a strong fit for this architecture. FastAPI handles lightweight, independently deployable services well — native async support, automatic OpenAPI docs, and low boilerplate. Flask works for simpler services. For larger monolith migrations, Django REST Framework brings full ORM and auth support, though it's heavier.
For production-grade microservices, FastAPI has become the default for most Python backend engineering teams.
Your monolith is why your deployments take a week
The shift to a Python microservices architecture is usually not about technology first — it's about reducing coordination overhead as systems and teams grow.
| Before (monolith) | After (Python microservices) |
|---|---|
| Full system redeploy for every change | Deploy individual services independently |
| Shared release cycle across all teams | Parallel development with clear ownership |
| Entire system fails on one service bug | Failures isolated per service |
| Scale the whole app for one bottleneck | Scale only the service under load |
| High-risk, infrequent deployments | Per-service CI/CD, frequent and boring |
At a small scale, a monolith works well. But as more engineers and features get added, things start slowing down—not because of performance, but because of people and process.
Team scaling becomes the bottleneck
As teams grow, everyone works on the same codebase — more merge conflicts, slower reviews, shared release cycles. This is Conway's Law. Microservices create clear ownership boundaries. Instead of everyone touching the same code, one team owns Order Service, another owns Payment, another owns Delivery.
Splitting by business capability works better than splitting by technical layer.
Deployment becomes painful
In a monolith, even a small change requires deploying the entire system. A bug in Payment delays a Delivery feature release.
With Python microservices, only the changed service gets redeployed. Other services keep running. The goal: frequent, small, boring deployments.
Failure should not break everything
In a monolith, one issue can bring down the entire system. With microservices, failures stay contained. If Delivery Service goes down, the system can still accept orders — orders get marked as "awaiting dispatch." The blast radius is limited.
Scaling efficiently
Traffic spikes hitting one part of the system don't require scaling everything. Scale Order Service. Payment and Delivery stay at their current footprint. This is where Kubernetes autoscaling makes Python microservices genuinely cost-efficient at scale.
When NOT to split yet
Microservices are not always the right first step.
Avoid splitting if:
- Service boundaries are unclear
- APIs are not stable
- CI/CD and monitoring are weak
In such cases, a well-structured modular monolith is usually a better approach.
Faster deployments, harder debugging — the microservices trade-off
Microservices don't remove complexity — they move it. In a monolith, complexity lives in the code. In microservices, it shifts to runtime behavior:
- Multiple services instead of one process
- Network communication instead of function calls
- Independent deployments instead of a single release
This introduces real-world problems that don't exist in a monolith:
- Network calls can fail
- Requests can time out
- Messages can be duplicated
- Some parts of the system can be down while others are running
You're no longer debugging a single application — you're debugging interactions between services.
What this means in our system
Take a simple failure scenario:
- User places an order → Order Service works fine
- Payment Service is down
Now we have a problem: the order is created but payment is not completed. The system is inconsistent. This is not a bug — it's a natural outcome of distributed systems.
Design for it from day one:
- The network is unreliable → use timeouts and retries
- Latency exists → avoid long chained calls
- Services scale dynamically → no hardcoded dependencies
- Ownership is distributed → clear responsibilities and monitoring are critical
Consistency is no longer guaranteed — and that's okay
In a monolith, consistency is simple — one database transaction keeps everything in sync. With Python microservices, that guarantee is gone. Different services can temporarily have different views of the system. This isn't a flaw — it's a design choice.
Eventual consistency in practice
When a user places an order:
- Order Service creates the order → status: PENDING
- Payment Service processes payment separately
For a short window, the order exists but payment isn't confirmed. This is expected.
Eventually, the system settles:
- Payment succeeds → order becomes COMPLETED
- Payment fails → order becomes CANCELLED
This is eventual consistency — things may be temporarily out of sync, but they converge over time.The real shift in thinking: instead of asking "is
everything consistent right now?" ask "what must be immediately correct, and what can converge over time?"
- Showing a slightly delayed order status → usually fine
- Charging a customer twice → never acceptable
How to make this work in production:
- Reliable event publishing via the transactional outbox pattern
- Idempotent consumers to handle duplicates safely
- Derived views for querying (order status view built from events)
Decouple your services, eliminate cascading failures, scale on demand
Early Python microservices often communicate over HTTP. It looks simple, but creates hidden coupling: if Service B is slow, Service A is slow. If B is down, A fails. You've split the code but not the coupling.
Event-driven architecture breaks this. Instead of Service A asking "did the payment succeed?", it receives a PAYMENT_SUCCESS event and reacts independently. Services communicate through facts, not requests.
Core concepts:
- Event — an immutable record of something that happened.
ORDER_CREATED,PAYMENT_FAILED. Past tense, always - Command — a request for something to happen.
CapturePayment. Imperative - Notification vs domain event — notifications are FYI; domain events are meaningful business facts other services build workflows on
- Schema evolution — events outlive code. Add fields backwards-compatibly and version carefully
- Ordering — don't assume global ordering. Scope it per
orderIdand design for out-of-order delivery
Early microservices often communicate via HTTP calls.
This looks simple on paper, but it creates hidden coupling:
- Service A waits for Service B
- If B is slow → A is slow
- If B is down → A fails
Event-driven systems break this dependency.
Instead of asking - “Did the payment succeed?”, we say - “Payment succeeded” (as an event)
Now other services react independently. This reduces coupling and improves resilience — but introduces eventual consistency, which is why the next two sections matter.
Centralized authentication via API gateway
API Gateway provides centralized security, routing, observability, and request management, while Load Balancers ensure high availability, scalability, and efficient traffic distribution across microservice instances. Let's check it features.
A. Authentication and Authorization: API Gateway validates JWT/OAuth tokens before forwarding requests to backend services.
Benefits
- Centralized security
- Reduced duplicate authentication logic
- Faster microservice development
B. Rate Limiting: Controls how many requests a user or client can send within a time window.
Benefits
- Prevents API abuse
- Protects services from overload
- Improves system stability
C. Request Aggregation: Combines responses from multiple microservices into a single response for the frontend.
Benefits
- Reduces frontend API calls
- Improves response time
- Simplifies frontend logic
D. Circuit Breaker: Stops requests temporarily to unhealthy or slow services to avoid cascading failures.
Benefits
- Improves fault tolerance
- Prevents system-wide outages
- Enhances service reliability
E. Logging and Monitoring: Captures request logs, metrics, response times, and tracing information centrally.
Benefits
- Easier debugging
- Better observability
- Faster issue detection and monitoring
Saga pattern — how microservices stay consistent
In Python microservices, there's no single database transaction across services. When something fails, you can't roll back across service boundaries. The saga pattern handles this.
A saga breaks a business flow into discrete steps. Each service does its part. If something goes wrong, we don't roll back — we apply compensating actions (business-level "undo").
How it works in our system
Let’s walk through our order flow:
Step 1: Order created
- Order Service creates order →
PENDING - Emits
ORDER_CREATED
Step 2: Payment Processing
- Payment Service consumes the event
- Processes payment
Now two outcomes:
On payment success
- Emits
PAYMENT_SUCCESS - Order Service updates →
COMPLETED - Delivery Service is triggered
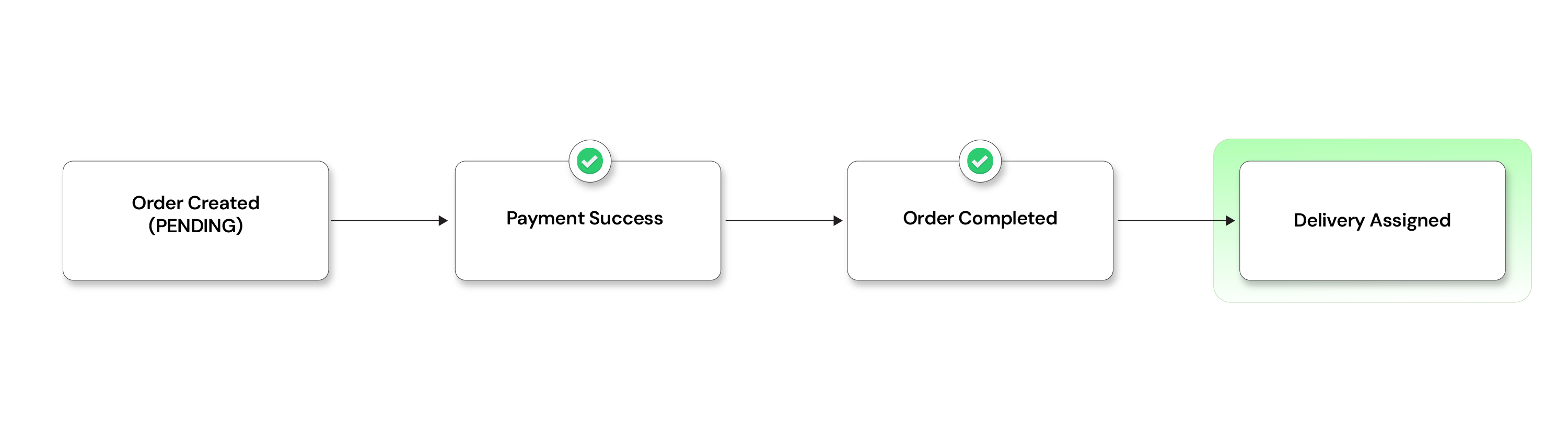
On payment failure:
- Emits
PAYMENT_FAILED - Order Service updates →
CANCELLED
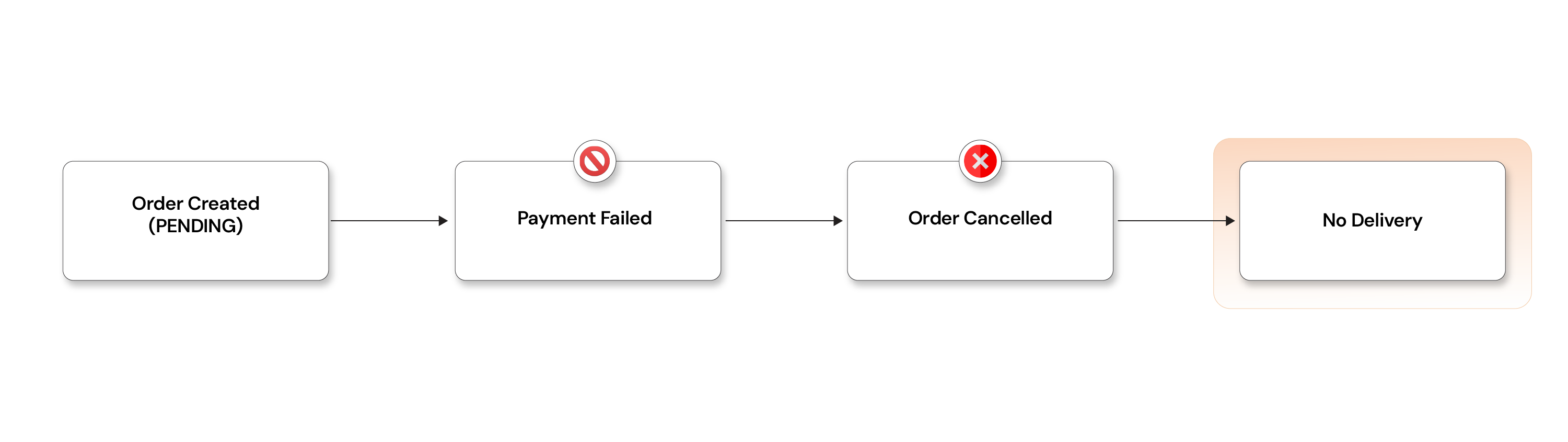
This is the key idea: We are not rolling back; we are moving forward with corrective actions.
What “Compensation” means
Compensation is not a technical rollback—it’s a business decision. Here are a few examples:]
- Payment fails → cancel the order
- Delivery already assigned → cancel or reroute delivery
- Payment reversed later → issue refund, stop shipment if possible
It may not perfectly undo everything, but it keeps the system consistent and predictable.
Two ways to implement sagas
- Choreography → services react to events directly. Simple, but can get hard to trace as the workflow grows
- Orchestration → a central service controls the flow. More explicit, easier to monitor, but adds a dependency
In most production systems, orchestration wins once the workflow has more than three or four steps.
Idempotency — Handling duplicate events
In Python distributed systems, duplicates are normal — not rare. Retries, restarts, and network issues mean the same Kafka event can be delivered more than once. If your system isn't designed for this, data corruption is a matter of when, not if.
Idempotency means processing the same event multiple times still produces the same result.
What this looks like in our system
Without idempotency:
ORDER_CREATED(order_id=123) ORDER_CREATED(order_id=123) → Payment processed twice
With idempotency:
- First event → processed normally
- Second event → safely ignored
Each event carries a unique event_id. Processed IDs are stored in Redis. If the same event arrives again, it gets skipped.
Other approaches: idempotency keys on API requests, state checks (update only if order is still PENDING).
Failure handling — designing for things going wrong
In production Python microservices, failures are not edge cases — they're normal. Services crash, networks fail, dependencies slow down. The goal is not to avoid failure but to handle it without breaking the system.
What this looks like in our system
Scenario: Payment Service crashes during processing
- Retry → try the request again (many failures are temporary)
- Backoff → wait before retrying (1s → 2s → 4s) to avoid overload
- Circuit Breaker → if failures continue, stop calling Payment for a while
This prevents one failing service from slowing down the entire system.
Key practices we follow
- Timeouts → never wait indefinitely
- Retries with backoff → handle temporary issues
- Circuit breakers → avoid cascading failures
- Rate limiting → protect against traffic spikes
- Bulkheads → isolate resources so one issue doesn’t consume everything
- Dead-letter queue (DLQ) → store repeatedly failing events for later
- Graceful degradation → return partial responses when possible
Observability — from guessing to knowing
In a Python microservices system, debugging isn’t straightforward anymore. A single user request flows through multiple services.
Without observability, you’re basically guessing what went wrong.
Observability means being able to understand system behaviour from the outside—clearly and quickly.
Scenario: a user reports "money got deducted but the order was cancelled."
Without observability:
- You’re guessing where things broke
With observability:
- Use a correlation ID to track the request
- Follow it across Order → Payment → Delivery
- Identify exactly where it failed
What makes this possible
We rely on a few key pieces:
- Structured logs → machine-readable, searchable event records per service
- Metrics → request rate, error rate, latency per service (this is what drives alerts)
- Tracing → an end-to-end view of a request as it crosses service boundaries
- Correlation ID → a single identifier threaded through every log entry for a given request
Common production tooling: Prometheus and Grafana for metrics, Jaeger or Tempo for distributed tracing, ELK stack or Loki for log aggregation.
Teams scaling Python microservices on Kubernetes often find observability is the first thing that breaks under load. For production-hardened approaches, see Opcito's guides on Kubernetes observability and monitoring and cloud-native application delivery patterns.
Why it matters
Observability helps answer critical questions:
- Which request failed?
- In which service?
- Why did it fail?
Final mental model to keep
A microservices system is not a single application. It’s a set of independent services working together to create one user experience.
In our system, you can think of it like this:
- Order Service → “I created the order”
- Payment Service → “I handled the payment”
- Delivery Service → “I’ll take care of delivery”
No single service controls everything. The system works through cooperation, not control.
What this means in reality
Since services communicate over a network, you must always assume:
- Delays will happen
- Failures will happen
- Duplicate events will happen
So instead of relying on perfect behaviour, we build guardrails into every service:
• Timeouts on every call
• Retries with backoff
• Idempotency for duplicate handling
• Strong observability (logs, metrics, tracing)
Quick production checklist
A healthy system usually ensures:
- Clear ownership and boundaries for each service
- Safe communication (timeouts + retries)
- Idempotent consumers (no duplicate side effects)
- Saga/compensation for critical workflows
- Full visibility into failures (what, where, why)
System design requirements
Services
- API Gateway
- Order Service
- Payment Service
- Delivery Service
Infrastructure
- PostgreSQL (data)
- Kafka (events)
- Redis (cache/idempotency)
POC design and complete flow
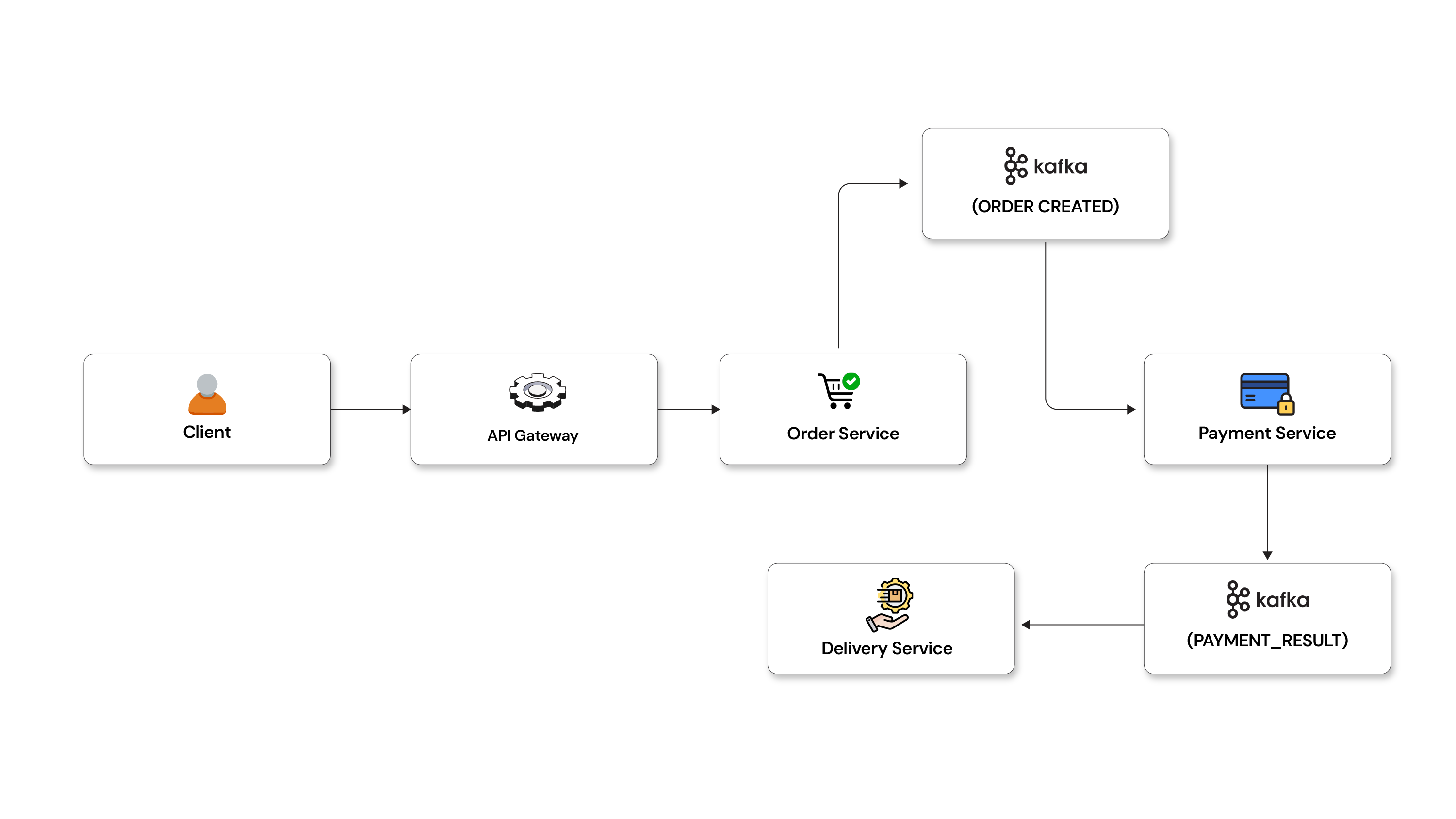
Implementation steps
STEP 1: Database model (order service)
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Order(Base):
__tablename__ = "orders"
id = Column(Integer, primary_key=True)
status = Column(String) # PENDING, COMPLETED, CANCELLED
STEP 2: Order service (saga start)
from fastapi import FastAPI
from sqlalchemy.orm import sessionmaker
from common.kafka_client import publish
import uuid
app = FastAPI()
@app.post("/orders")
def create_order():
order_id = str(uuid.uuid4())
# Save to DB with PENDING
event = {
"event_id": str(uuid.uuid4()),
"event_type": "ORDER_CREATED",
"order_id": order_id
}
publish("orders", event)
return {"order_id": order_id}
STEP 3: Payment service (with failure simulation)
from kafka import KafkaConsumer
import random, json
processed_events = set()
consumer = KafkaConsumer(
'orders',
bootstrap_servers='kafka:9092',
value_deserializer=lambda x: json.loads(x.decode())
)
for msg in consumer:
event = msg.value
if event['event_id'] in processed_events:
continue
processed_events.add(event['event_id'])
if event['event_type'] == 'ORDER_CREATED':
order_id = event['order_id']
success = random.choice([True, False])
new_event = {
"event_type": "PAYMENT_SUCCESS" if success else "PAYMENT_FAILED",
"order_id": order_id
}
print(new_event)
STEP 4: Order service (compensation logic)
if event['event_type'] == 'PAYMENT_FAILED':
order.status = "CANCELLED"
elif event['event_type'] == 'PAYMENT_SUCCESS':
order.status = "COMPLETED"
STEP 5: Retry logic
import time
def retry(func):
for i in range(3):
try:
return func()
except Exception:
time.sleep(2 ** i)
STEP 6: Idempotency using Redis
import redis
r = redis.Redis(host='redis', port=6379)
if r.get(event_id):
return
r.set(event_id, "processed")
STEP 7: Docker compose (FULL RUN)
version: '3.8'
services:
kafka:
image: bitnami/kafka
postgres:
image: postgres
environment:
POSTGRES_PASSWORD: password
redis:
image: redis
order-service:
build: ./order-service
payment-service:
build: ./payment-service
delivery-service:
build: ./delivery-service
api-gateway:
build: ./api-gateway
ports:
- "8000:8000"
RUN
docker-compose up --build
Full flow with failure simulation
- Order created
- Event → Kafka
- Payment randomly fails
- If fail → Order
CANCELLED - If success → Delivery triggered
What makes this advanced
- Real DB model
- Saga implemented
- Failure simulation
- Idempotency
- Retry logic
- Event-driven system
Production checklist
A healthy Python microservices system ensures:
- Clear ownership and boundaries per service
- No shared databases
- Safe communication (timeouts + retries on every call)
- Idempotent consumers (no duplicate side effects)
- Saga or compensation logic for critical workflows
- Full visibility into failures (what, where, why)
- Per-service CI/CD pipelines
- Kubernetes health checks and readiness probes on every service
Running Python microservices in production is one thing. Getting the architecture right from the start is another.
Most teams hit the same walls — unclear service boundaries, shared databases that create hidden coupling, observability gaps that only surface under load, and Kafka configurations that work in dev but fall apart in production.
Opcito has built and hardened production-grade Python microservices systems for enterprise ISVs and product companies across cloud-native infrastructure, Kubernetes deployments, and DevOps automation. We know where these systems break because we've fixed them.
If you're designing a new microservices architecture, migrating off a monolith, or trying to stabilise a system that's already in production — we can help you move faster with fewer surprises. Talk to our engineering team.





