















Posted By

In the 21st Century, data is the biggest commodity. The value you can rip out of data is immense. However, you need a sophisticated system to analyze data to get valuable insights. There are multiple sources of data in any IT operation. You can analyze data generated from applications, servers, networks, and infrastructure to detect potential issues. This operational data is primarily gathered through system-produced metrics and logs. Operations teams have always depended on manual human efforts to search and report on operational data. But now, organizations are embracing automated systems with intelligent machine learning tools to alert IT teams concerning the issues, their root causes, and recommended solutions without any human intervention.
For efficient IT operations, teams need more intelligent tools to reduce mean time to repair (MTTR) and eliminate time spent on the inefficient search for a cause in the data heap that is not impacting an outage. One prominent name in this space is Elasticsearch. Elasticsearch's machine learning implements unsupervised and supervised learning algorithms to sort through operations data. It facilitates more effective alerting and graphical visualizations of operational data by identifying unusual activity based on analysis. With the help of a user-friendly interface, the Elastic Stack enables real-time search, reporting, and analysis of streaming metrics and logs.
Elasticsearch machine learning for enhanced IT operations
Organizations with excellent IT operations tend to excel at every aspect of business performance, including profitability, decision-making, investments, and more. This is precisely why IT operations need more intelligent solutions to detect and resolve issues related to applications and infrastructure. And if something is not right, the administrator must identify and flag the error in log data. Elasticsearch's machine learning identifies unusual errors by modeling the data and notifying the operational team about the anomalies to help them forecast future behaviors. It simply gives a comprehensive view of the incident by determining how the system has changed compared to the day before.

Elasticsearch acts as an essential understructure for monitoring application metrics and logs. Once the metrics and logs are collected, we need to leverage the power of Elasticsearch to query our data. With the rising volume of data, you can't possibly eyeball so many time charts to find out what's going on. But Elasticsearch machine learning allows you to monitor and model multiple entities at one go and identify unusual behaviors mathematically. You have to put a threshold or a rules-based alert which are static in nature to find out issues using standard search techniques. Typically, one doesn't know where to set those bounds, as they become too rigid for dynamically changing data. Optimizing these thresholds while avoiding false positives is a tedious process. Elasticsearch Machine Learning allows the alerts to be more dynamic by learning the normal behavior models and alerting when data doesn't fit the model.
Getting started with Elasticsearch machine learning
Elastic offers different machine-learning algorithms that allow you to model your data. Unsupervised Learning can deduce patterns in your data without training or intervention. There are two types of unsupervised analysis: anomaly detection and outlier detection. Whereas supervised learning requires training data sets: classification & regression. Let’s get started with a machine learning setup in Elasticsearch and anomaly detection.
Setting up machine learning features in Elasticsearch
It is mandatory to have at least one machine learning node in your cluster to set up the machine learning features in Elasticsearch. A machine learning node is a node that must have the following values:
- xpack.ml.enabled: true, allows machine learning APIs on the node.
- node.role: ml, identifies the node as a machine learning node.
Getting started with anomaly detection
To explain the process, I will be using sample log data from Kibana.
-
From the Kibana Main Menu, select “Machine Learning.”

-
From the Anomaly Detection tab, select “Create Job.”
-
Select your index pattern or saved search:
Here, I have selected kibana_sample_data_logs.
- You can create different types of jobs. For instance, I am taking the basic single metric job.
-
Here, you can select the time range or run the job on the complete data set
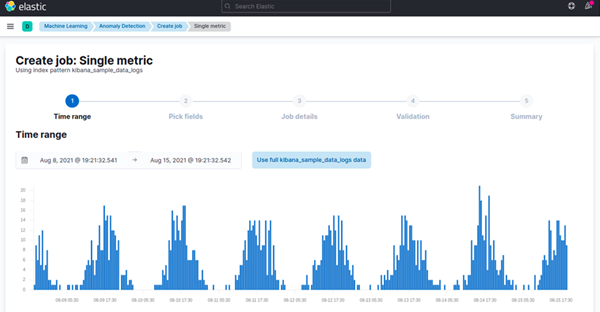
"Pick Fields" helps you select the metric you are interested in. Fill up the job details like a name. Finally, hit "Create Job." The job will start running automatically. It will retrieve a subset of data using the data feed you have defined and build the model using unsupervised machine-learning techniques. Bucket, a machine learning feature, uses this concept to divide time-series data into batches for processing. The Bucket Span defines the time interval used to model the data. It considers the granularity, frequency of data input, duration of anomalies, and frequency of alerting required.
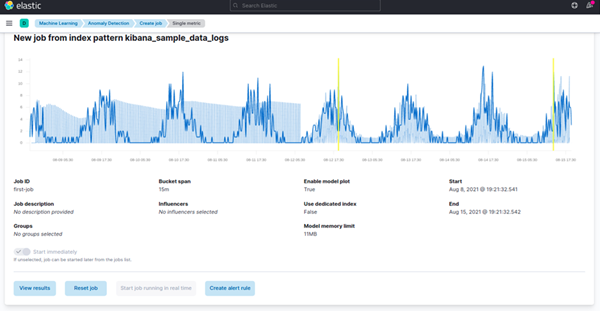
-
You can run the job in real time for new data, which will help detect anomalies as they happen. Go to view results to find results in a single metric viewer, where you will be able to select the time range you want to inspect.
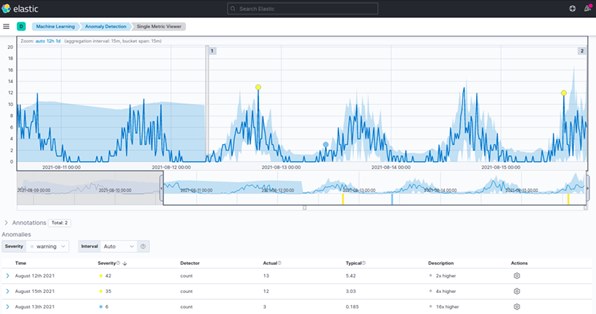
The blue line represents the actual data, and the shaded part gives the expected values according to the model. This range becomes more accurate as the model matures by processing more data.
-
Each anomaly is given an anomaly score between 0-100 which defines the severity of the anomaly. It gives an idea of how anomalous a data point is.

You can even inspect each anomaly to see its typical value that would have been at this time or switch to Anomaly Explorer to view a swimlane showing anomalies over time.
-
Add this swimlane to a dashboard to spot new anomalies as soon as they are detected.
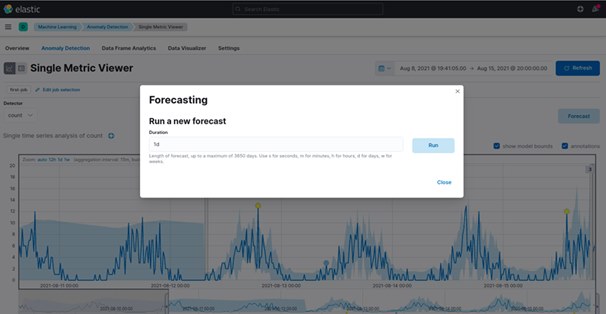
Once the model is created, use the forecast option to predict future behavior, typically valid for capacity planning. You can use the forecast to estimate the probability of a time-series value occurring at a future date, for instance, determining if the disk utilization will go above 90% in the next ten days.
Forecast asks you to specify a duration, which shows how far the forecast extends beyond the processing of the last record. The default value is one day. The farther you forecast, the lower the confidence level goes. Eventually, the forecast will stop if the confidence levels go too low, or you can set it when the forecast expires. The results get deleted after a forecast expires. The default value is 14 days.
Anomaly detection is one of the many options provided by Elasticsearch to optimize a machine learning job as required by your environment. Start creating your anomaly detection jobs to simplify daily operations or explore more to create complex analysis functions as necessary. Get in touch with our experts to know more about enhancing your IT operations with Elasticsearch machine learning.


Related Blogs



