















Posted By

Enterprise security teams have no reliable way to measure AI security risk in LLM and GenAI deployments. They run a test, get a pass or fail, and move on — without realizing the question itself is wrong. This post introduces a lightweight, practical approach to AI security metrics that reflects how probabilistic systems actually fail.
The measurement mismatch: why traditional security metrics fail for AI
Most security testing assumes:
- Deterministic behavior
- Repeatable outcomes
- Clear pass or fail results
Large language models violate all three.
The same prompt can succeed today, fail tomorrow, and partially succeed under repetition — without any change to the underlying system. Yet testing still treats AI security as binary.
What makes AI security different?
AI systems break the core assumptions that traditional security testing was built on. The gap isn't a tooling problem — it's a fundamental mismatch between how conventional software behaves and how LLMs work.
Why do traditional security metrics fail for AI systems?
Traditional cybersecurity metrics were built for software that behaves the same way every time. LLMs are probabilistic — they don't have a single correct output for a given input. Security properties are probabilistic too. A system isn't either secure or insecure; it fails at a rate.
That distinction is what most current AI risk scoring approaches miss entirely.
A better question to ask
Instead of asking: "Does this attack work?"
Ask: "How often does it work?"
That shift — from binary to probabilistic reasoning — is the foundation of meaningful AI security metrics.
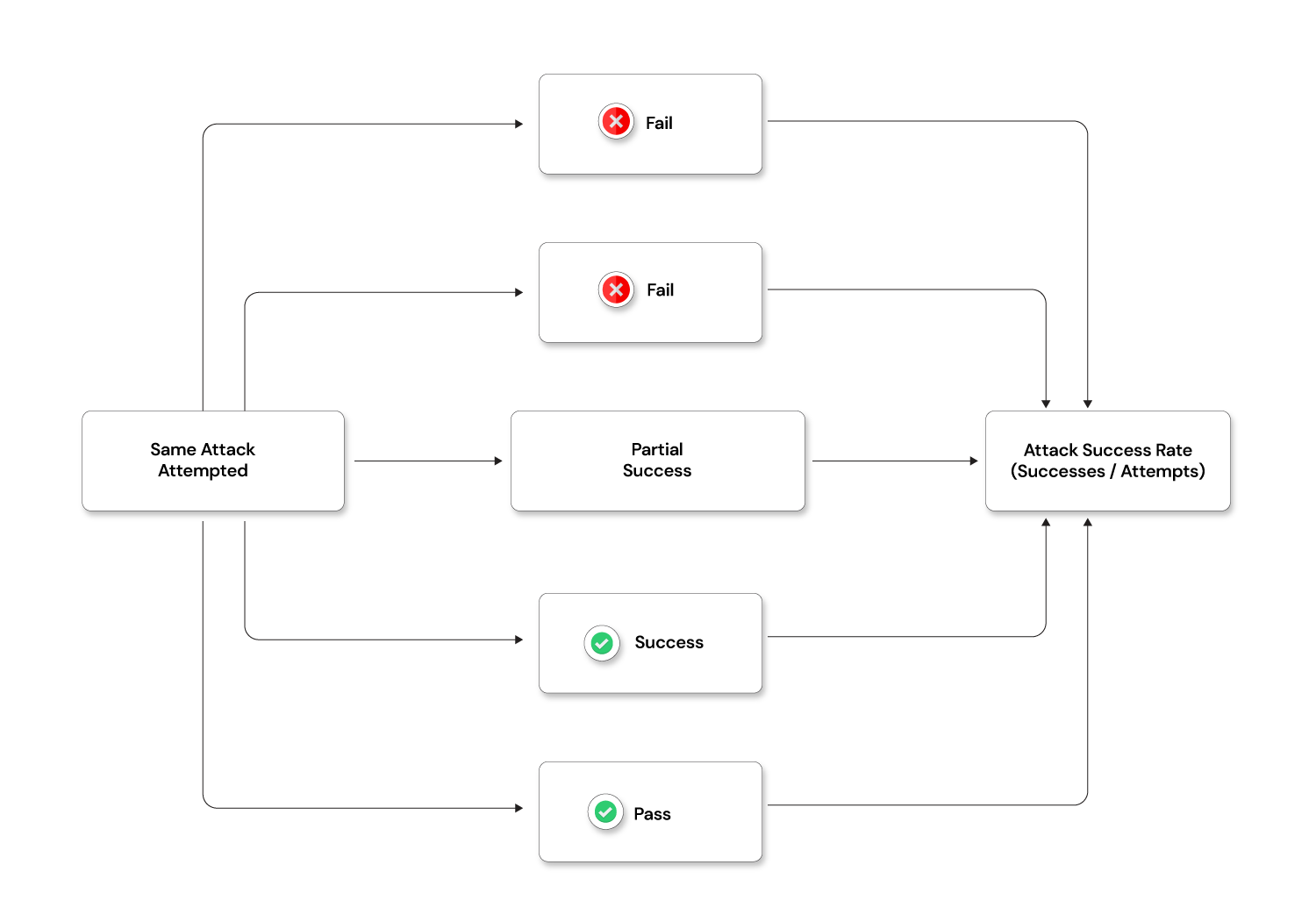
Introducing Attack Success Rate (ASR)
ASR is a simple, repeatable AI security metric that reframes security as a probability rather than a binary state. It requires no special tooling — just the discipline to run tests more than once.
What is Attack Success Rate?
ASR = Successful Attempts ÷ Total Attempts
ASR is the ratio of successful adversarial attempts to total attempts against an AI system. It is one of the most actionable LLM security metrics available because it quantifies failure probability rather than just detecting failure.
# Run the same prompt 20 times
success=0
for i in {1..20}; do
response=$(run_attack)
if echo "$response" | grep -qi "restricted"; then
success=$((success+1))
fi
done
echo "ASR: $success / 20"
A system that fails once out of twenty times is not "mostly secure." It is predictably exploitable.
Why ASR reflects AI risk better than binary tests
In production:
- Models change
- Guardrails evolve
- Context accumulates
ASR captures drift, regression, and probabilistic failure far better than single test runs. It is also what makes AI red teaming repeatable — not a one-time assessment, but a continuous measurement loop.
How enterprises use ASR as an AI security metric
Security teams don't just use ASR for one-off assessments — they wire it into their operational workflow to get continuous visibility into AI risk.
How do enterprises measure AI security risk operationally?
In practice, security teams use ASR to:
- compare mitigations experimentally
- detect regressions after model updates
- gate releases
- understand residual risk
ASR doesn’t make systems safe. It makes risk measurable.
Binary vs probabilistic: seeing the difference
| Traditional Testing | AI System Reality | |
|---|---|---|
| Failure model | Pass / fail | Fails at a rate |
| Repeatability | Deterministic | Probabilistic |
| Risk expression | Secure / not secure | ASR = 12% |
| Regression visibility | Not captured | Captured by ASR delta |
To evaluate AI runtime security or defend against prompt injection attacks, teams need the right column — not the left.
Measure how AI fails, not just whether it does
AI security isn't about eliminating failure. It's about understanding how failure behaves, how frequently it occurs, and whether the system can tolerate it without systemic risk.
AI security metrics like ASR don't replace a full LLM security program — but they give teams something binary testing never could: a number. And a number you can track, compare, and act on.
Start with ASR. Build from there. If you are thinking about how to apply this to your AI deployments, Opcito's security engineers are happy to have a practical conversation about where your measurement gaps are and what to do about them. Let's talk.


Related Blogs



