















Posted By

High-Availability Cluster is a group of computers with the purpose of increasing the uptime of services by making sure that a failed machine is automatically and quickly replaced by a different machine with little service disruption.
In this blog, I will explain how you can set up a Jenkins High Availability (HA) cluster using the data replication software DRBD and the cluster manager Heartbeat. In this example, the two machines building the cluster run on Ubuntu 16.04. I will also talk about how to switch between the active and passive machines in case of failover.
Before we jump onto the actual setup, let’s see the tools and services you will need in HA cluster:
- Distributed Replicated Block Device (DRBD)
The DRBD software provides synchronization between the active and passive machines. In this particular case, DRBD will replicate the Jenkins data stored inside the block devices. - Pacemaker and Corosync
Pacemaker and Corosync are the tools that will be used for communication and managing clusters. Corosync enables servers to communicate as a cluster, while Pacemaker provides the ability to control how the cluster behaves. - Heartbeat
Heartbeat is a service that will manage the high IP availability and other services in your servers. - Virtual IP
The virtual IP address is an IP address that will always point to an active machine. A user can access the application using virtual IP.
Configuration of Jenkins HA cluster
For the configuration of Jenkins High availability cluster, we will take an example of Jenkins as a highly available application. Jenkins will be installed on both active and passive machines. For accessing the Jenkins application from the browser, we will not use an active server or passive server IP address. Here we will use a virtual IP for accessing Jenkins UI, which will always point to the active server IP address. If the active server goes down, the virtual IP will be switched to the passive server.
For this configuration, we will need the following hardware, software, and networking elements:
- HA cluster for Jenkins application: we need 2 physical or virtual machines
- Ubuntu 16.04 on both machines
- Create both machines in the same network with active internet connectivity.
Assumptions:
Virtual IP: 192.168.122.10 - This will be our high-availability IP. Our Jenkins application may need to point to this IP. This IP will be available only on the active server. If the active server goes down, it will be switched to a passive server.
Active Server: 192.168.122.124 - This will be the active server.
Passive Server: 192.168.122.195 - This will be the passive server or what we call “a backup server”.
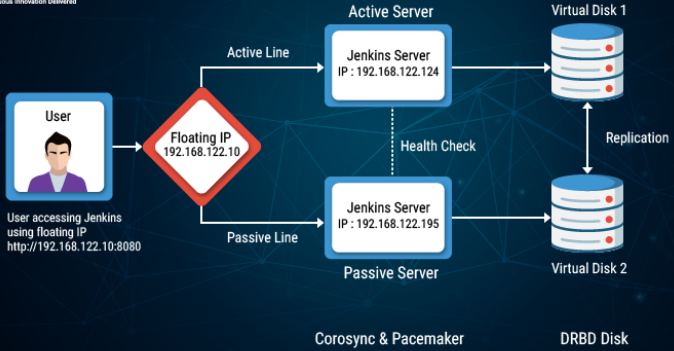
Implementing the Jenkins HA cluster
Now we will configure and install Corosync, Pacemaker, and DRBD tools on both machines. Before installing tools on machines, we need to edit the host file, NTP file, and apt-get repo files.
Note: For performing the following steps, we need access to a sudo user.
Step 1: We need to update the host file on both instances with IP and hostname. Also, configure the NTP tool on both machines so, both machines will be in sync for data replication.
Step 2: Install the Jenkins server on both machines. Configure the security, and add the users in Jenkins on both machines. In this article, we have assumed /var/lib/jenkins will be the home directory for Jenkins.
Step 3: Now, create a small Virtual Hard Disk on both instances for data replication purposes. For our scenario, we will create a virtual disk of size 1 GB for both instances.
Attach this created virtual disk to your instances, format the partition and mount it to the Jenkins home directory. Use tools such as dd, mkfs, mount, etc. for formatting and mounting purpose.
Step 4: Now, install the DRBD package on both instances. Add the IP address and partition details of both machines into /etc/drbd.conf. Perform the steps of DRBD cluster configuration. The following steps will create a mirror device on both machines and will make the active server a primary server of the DRBD cluster.
active/passive# drbdadm create-md jenkins-ha active/passive# /etc/init.d/drbd start active/passive# drbdadm up jenkins-ha active# drbdadm -- --overwrite-data-of-peer primary jenkins-ha/0
Note: drbdadm is an administration tool for DRBD that provides a CLI to configure the DRBD.
Step 5: Next step is to configure Pacemaker and Corosync on both machines. Before that, we need to disable DRBD and make the mirror device down by running drbdadm down jenkins-ha on both machines.
Step 6: Install the Pacemaker on both machines. Also, install haveged on the primary machine for generating auth keys and transfer these auth keys into Corosync directory.
Step 7: As Corosync helps nodes to communicate in the cluster, we need to provide details of both machines into /etc/corosync/corosync.conf file. After adding the details, you need to restart the Corosync service. Now, we can see both the nodes as online using command (crm status).
Step 8: Up till here, we have configured DRBD, Pacemaker, and Corosync on both machines. Now we will add virtual IP and Heartbeat resources for cluster communication purpose.
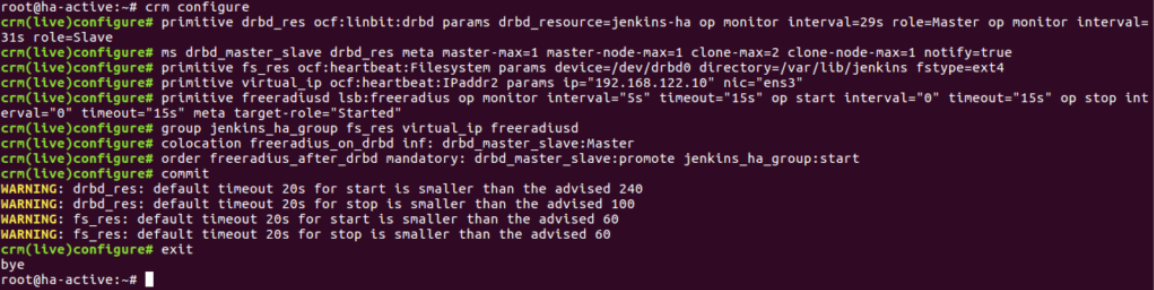
Once we add these resources, our virtual IP will be ready to point to the Jenkins application on the active server.
Testing Failover Scenario:
Now we have the Jenkins application running on both machines. We can access the Jenkins application using the individual IP address of machines. But we will access Jenkins using Virtual IP which will be pointing to active server initially. In case of failure of the active server, the virtual IP address will point to the passive server. DRBD blocks will replicate the data to the passive server, so there is no need to worry about the data on the active server.
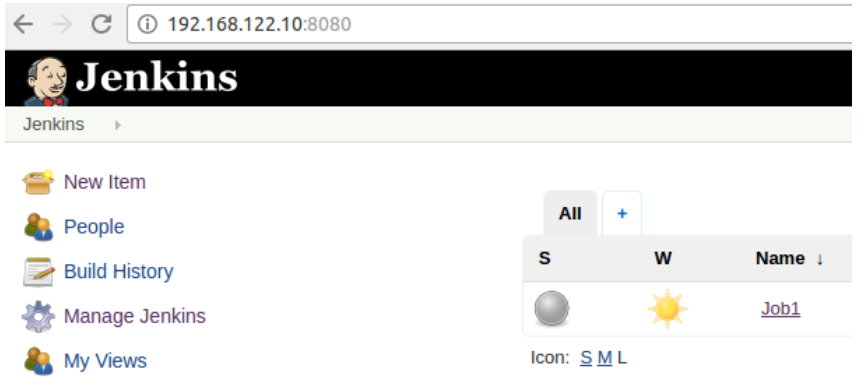
Fig.1 - Accessing active server Jenkins using virtual IP.
We have created job1 on the Jenkins server using virtual IP. Ultimately it will be created on the active server. You can check that by opening an active Jenkins server. But you will not be able to see this job1 on the passive server as it is in a passive state.
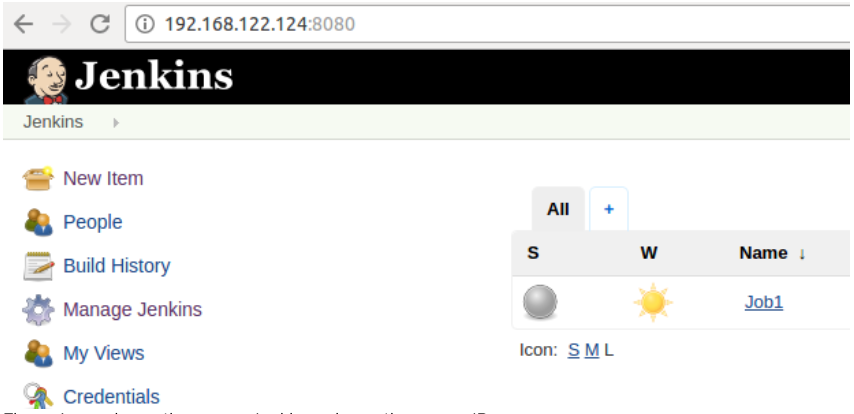
Fig.2 - Accessing active server Jenkins using active server IP.
Fig.3 - Accessing passive server Jenkins using passive server IP.
Now, here we want to check the failover scenario. Right now, the virtual IP is pointing to the active server, so we will shut down the active server. Then the virtual IP should automatically point to the passive server. You can see the job1 is not available on the passive server in fig.3. Now check the fig.4 which is after shutting down the active server.

Fig.4 - Accessing passive server Jenkins using passive server IP.
We can also achieve high availability using different cloud providers' services. But, those services will not be cost-effective. Using open source tools like Pacemaker and DRBD is a cost-effective way to have high availability solutions and DRBD will always have added advantage over centralized data storage with decentralized data storage in case of data disk failure.





