















Posted By
Data is the next big thing, and this has accentuated the importance of the way you manage your database. There are various operations that you perform with your database such as replication, partitioning, sharding, etc. These operations, most of the time, are not necessarily mutually exclusive. Database replication is one of the key operations when it comes to data recovery, fault tolerance, and consistency.
It’s almost a decade now that MongoDB is pretty much there in the database landscape. I am sure pretty much everyone who has tried their hands on MongoDB is aware of what replica set and sharding is, and when it comes to fault tolerance, replica set is great to have in your infrastructure.
In this blog, I am going to talk about how you can provision MongoDB replica set on GCP compute engine using Terraform that will be capable of self-healing in case of node failure. Plus, in order to manage load balancing, I want it to be auto-scaling. Following are a few major points I will be talking about in this blog:
- Steps to create GCP Managed Instance Group (MIG) using compute instance template
- Startup script for compute instance template resource
- To install MongoDB on nodes
- To find minimum IP within the nodes present in MIG
- To declare node with IP as a primary
- To add cron job for service discovery
- Manual verification of auto-scale and self-healing MongoDB replication nodes
- Terraform module conversion.
But before starting with the actual coding, let me clear the difference between auto-scaling and auto-healing. Auto-scaling helps replication to increase or decrease the total number of nodes in a replica set and is mainly used for load balancing. Consider a scenario where 3 nodes are handling the traffic to 90% of their capacity. Auto-scaling will spin up a new node in a replica set to manage the load in case the load increases. Whereas auto-healing is the next avenue in auto-scaling. Auto-healing helps the newer nodes sync with the existing nodes. It also helps to add a new node to replace a dead node.
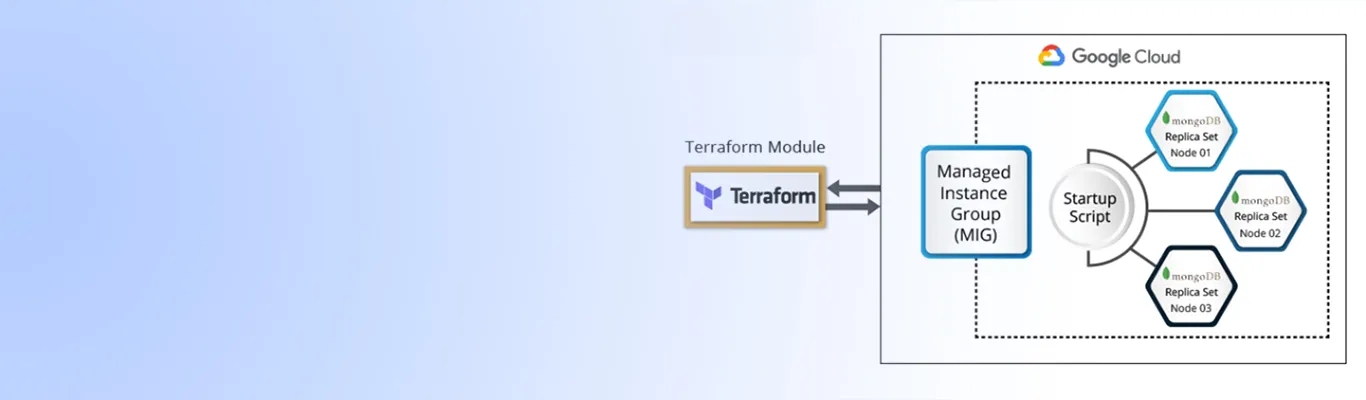
So just a few days back, while I was working on a project for one of our clients, I got a task in which I had to modify one Terraform script to make it self-healing. The script previously had a replica set setup on GCP Compute Engine, and it needed a few improvements to have auto-healing, fault-tolerance, and minimum replica set member management in order to achieve load balancing. The script was based on separate Compute Engines. So, the first obvious step was to scrap the existing script and redraw the architecture of the replica set. My initial approach was to utilize the existing features and resources to minimize my work. So, I moved to GCP Managed Instance Group (A managed instance group uses an instance template to create a group of identical instances. You can control a managed instance group as a single entity.) in order to achieve auto-scaling. So, let’s see how you can provision GCP Managed Instance Group using Terraform.
Create a GCP Instance Group Manager
resource "google_compute_instance_group_manager" "instance_group_manager" {
name = "${var.cluster_name}"
base_instance_name = "${var.cluster_name}"
zone = "${var.zone}"
target_size = "${var.total_nodes}"
}
This is a basic Terraform resource for any GCP Managed Instance Group or, as mentioned, Instance Group Manager.
Create a GCP Instance template and assign it to Instance Group Manager
Every MIG (Managed Instance Group) requires a template in order to provision instances. So, let’s create one GCP compute instance template and add an instance_template key to the MIG resource. Your Terraform script will look like this:
resource "google_compute_instance_template" "master_instance_template" {
machine_type = "${var.machine_type}"
region = "${var.region}"
// boot disk
disk {
auto_delete = true
boot = true
source_image = "${var.image_id}"
type = "PERSISTENT"
disk_type = "pd-ssd"
}
// networking
network_interface {
subnetwork = "default"
access_config = {}
}
lifecycle {
create_before_destroy = true
}
service_account {
email = "${var.service_account_email}"
scopes = "${var.service_account_scopes}"
}
}
resource "google_compute_instance_group_manager" "instance_group_manager" {
name = "${var.cluster_name}"
instance_template = "${google_compute_instance_template.master_instance_template.self_link}"
base_instance_name = "${var.cluster_name}"
zone = "${var.zone}"
target_size = "${var.total_nodes}"
}
Note: In the above resource configuration, there are a few things that cannot be changed, such as the scope for the service account should be ["userinfo-email", "compute-rw", "storage-rw", "logging-write"]. You can add new scopes, but keep the above scope in the list. As you can see that there is one compute engine template added in Terraform configuration, and the link is given in the MIG configuration for that template.
Here is a Terraform variable file for your reference
variable "replicaset_name" {
default = "rs1"
}
variable "cluster_name" {
default = "mongodb-cluster-1"
}
variable "zone" {
default = "us-east1-b"
}
variable "project" {
default = ""
}
variable "region" {
default = "us-east1"
}
variable "machine_type" {
default = "f1-micro"
}
variable "image_id" {
default = "projects/ubuntu-os-cloud/global/images/ubuntu-1404-trusty-v20180913"
}
variable "total_nodes" {
default = "3"
}
variable "service_account_email" {
default = ""
}
variable "service_account_scopes" {
type = "list"
default = ["userinfo-email", "compute-rw", "storage-rw", "logging-write"]
}
Now that you are done with infrastructure deployment let’s see how to install MongoDB on the provisioned MIG. To automate the MongoDB installation and replica set setup, I am going to use Compute Engine feature startup script. If you’re familiar with Compute Engine, it’s likely that you want to use startup scripts to install or configure your instances automatically.
Now let’s start the shell script writing to install and set up the MongoDB replica set.
Install MongoDB using a startup script
I always recommend the latest and stable release of MongoDB. So, let’s install MongoDB 4.0.
# Make db directory sudo mkdir -p /data/db # Install MongoDB at startup sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list sudo apt-get update sudo apt-get install -y mongodb-org # Change bindIp of MongoDB from localhost to open for all sudo sed -i 's/bindIp: 127.0.0.1/bindIp: 0.0.0.0/g' /etc/mongod.conf # For more operations this service has been kept as down for the time being sudo service mongod stop
Above code will install MongoDB on Compute Engine Instance whenever any Instance gets deployed within the present MIG. The next step here is to set up a MongoDB replica set within the MIG and set one primary node.
Detect minimum IP from in the MIG
I am using min IP from the MIG to declare it as a master or a primary node. The logic behind this is max IP can differ because the number of nodes can increase in the replica set resulting in an increase in the max IP. Like, if a user wants more nodes than current nodes, then it will change the max internal IP of a replica set. So every time a new node is added, it will be considered as a primary node, and this will create a problem for the replica set as the newly added node will be considered as a master of another replica set with the same name as the existing replica set. That’s why I am using minimum internal IP to declare the master node.
# Export internal IP of the machine which we will need for other operations
export INTERNAL_IP=$(ifconfig | grep -Eo 'inet (addr:)?([0-9]*\.){3}[0-9]*' | grep -Eo '([0-9]*\.){3}[0-9]*' | grep -v '127.0.0.1')
# Get number of instances in MIG and get names of all instances in Group
sudo gcloud compute instance-groups list-instances ${cluster_name} --zone ${zone} > instances.txt && sudo sed -i '1d' instances.txt && cat instances.txt
# Start MongoDB with replica set option which is --replSet
nohup sudo mongod --port 27017 --replSet ${replicaset_name} --bind_ip localhost,$INTERNAL_IP &
count=$(wc -l < instances.txt)
seconds=$(($count*5+20))
current_hostname=$(hostname)
sleep $seconds
# Iterate over the internal IPs of VMs to findout min IP in a group.
filename="instances.txt"
min_ip=0
min_value=''
primary_host=''
while read -r line
do
row="$$line"
IFS=' '
read -ra array <<< "$$row"
ip=$(ping -c 1 $array | head -1 | grep -Eo '?([0-9]*\.){3}[0-9]*' | grep -Eo '([0-9]*\.){3}[0-9]*')
oc4=$${ip##*.}
if [ -z "$$min_value" ]
then
min_value=$oc4
min_ip=$ip
primary_host=$array
fi
if [ $min_value -gt $oc4 ]
then
min_value=$oc4
min_ip=$ip
primary_host=$array
fi
done < "$filename"
Here, I am trying to bootstrap the MongoDB service with --replSet flag, which means that the service will start in the replica set node.
Also to choose primary at an initial stage, you will have to choose any of the available instances. But this is not as easy as it looks. Let me elaborate on the issues you can face during this election. First of all, you cannot declare any of the nodes as primary, if you do so in the script, all VMs will be declared as primary nodes. As a result, every node will have its own replica set. There won’t be any communication between the nodes anymore. Also, at first provision, you won’t be able to decide which node is provisioned first. If you try it by yourself, then you will have to check it every time and you will have to list down the number of nodes that are provisioned from Terraform. Hence, there is no way to identify which node has been provisioned first among all of them.
To avoid this, you will have to ensure that only one node will be declared as a primary each time. If you go through the internal IPs then you will find out that there will be unique IP assigned to each machine every time. By taking advantage of this, you can declare the minimum IP node as a master in the very initial phase of the replica set configuration. And the loop from the above shell script will find the minimum IP from the MIG group.
Initiate master on the node with minimum internal IP and add others as secondary nodes
Now that the MIG is up, you have minimum IP at your disposal. Declare primary and secondary nodes. For that, check whether the current node is having minimum internal IP. If yes, then declare it as a primary or master node mongo --eval "rs.initiate()". Else wait for a few moments and add the current node in the replica set.
# If the current node is the same as min IP node/to be the primary node
# Then initiate replication on the same node and declare it as a primary node
# Else run a command on the primary node using gcloud ssh and add the current node in the replica set
if [ $current_hostname = $primary_host ]
then
echo "initiating primary"
echo "current_hostname => $current_hostname"
echo "primary_host => $primary_host"
mongo --eval "rs.initiate()"
else
echo "sleeping 30 secs"
sleep 30
echo sudo gcloud compute ssh --zone $(echo ${zone}) $(echo $primary_host) -- "\"sudo mongo --eval 'rs.add(\\\""$INTERNAL_IP:27017\\\"")'\"" > add_secondary.sh
sudo sh add_secondary.sh
sleep 15
sudo sh add_secondary.sh
sleep 15
clustered=$(mongo --eval "rs.status().errmsg" | sed '$!d')
string="no replset config has been received"
# Verify if the current node is added to replica set or not.
# If there is any issue while adding node to replica set then find out master node among the nodes present in MIG and add current node on that primary node.
if [ "$clustered"="$string" ]; then
echo "not added"
filename="instances.txt"
while read -r line
do
row="$line"
IFS=' '
read -ra array <<< "$row"
primary_found=$(mongo --host $array --eval "rs.isMaster().primary" | sed '$!d' | grep -Eo '?([0-9]*\.){3}[0-9]*')
if [ ! -z $primary_found ]; then
filename2="instances.txt"
while read -r line2
do
row2="$line2"
IFS=' '
read -ra array2 <<< "$row2"
ip2=$(ping -c 1 $array2 | head -1 | grep -Eo '?([0-9]*\.){3}[0-9]*' | grep -Eo '([0-9]*\.){3}[0-9]*')
if [ "$ip2"="$primary_found" ]; then
echo sudo gcloud compute ssh --zone $(echo ${zone}) $(echo $array2) -- "\"sudo mongo --eval 'rs.add(\\\""$INTERNAL_IP:27017\\\"")'\"" > add_secondary2.sh
sudo sh add_secondary2.sh
sleep 5
sudo sh add_secondary2.sh
break
fi
done < "$filename2"
clustered2=$(mongo --eval "rs.status().errmsg" | sed '$!d')
if [ "$clustered2"="$string" ]; then
break
fi
fi
done < "$filename"
else
echo "added"
fi
fi
Save the script with the name start-up-script.sh.
Add cron job to detect and recover MognoDB service on nodes
sudo echo '* * * * * root if [ "$(ps -ef | grep mongo | wc -l)"="3" ]; then echo "all is well" > /state.txt; else nohup sudo mongod --port 27017 --replSet '${replicaset_name}' --bind_ip localhost,'$INTERNAL_IP' & fi' > /var/spool/cron/crontabs/root
sudo chmod 0600 /var/spool/cron/crontabs/root
This code will help you make sure that MongoDB service is always up and running on nodes.
Add script to the template with parameters
As you can see in the shell script, I have mentioned a few variable names which are not declared anywhere, like zone, project, cluster_name, replicaset_name, service_account _email_log, service_account_scopes_log. These are the parameters that are taken from Terraform script. Let’s initiate this script from Terraform template file and make it runnable from Terraform.
data "template_file" "startup_script_mongodb_server" {
template = "${file("${path.module}/master-start-up-script.sh")}"
vars {
zone = "${var.zone}"
project = "${var.project}"
cluster_name = "${var.cluster_name}"
replicaset_name = "${var.replicaset_name}"
service_account_email_log = "${var.service_account_email}"
service_account_scopes_log = "${join(",", var.service_account_scopes)}"
}
}
Add script to GCP compute instance template
Once you have the script ready to install MongoDB and a set replica set, the Terraform configuration will look like this:
resource "google_compute_instance_template" "master_instance_template" {
machine_type = "${var.machine_type}"
region = "${var.region}"
// boot disk
disk {
auto_delete = true
boot = true
source_image = "${var.image_id}"
type = "PERSISTENT"
disk_type = "pd-ssd"
}
// networking
network_interface {
subnetwork = "default"
access_config = {}
}
metadata_startup_script = "${data.template_file.startup_script_mongodb_server.rendered}"
lifecycle {
create_before_destroy = true
}
service_account {
email = "${var.service_account_email}"
scopes = "${var.service_account_scopes}"
}
}
resource "google_compute_instance_group_manager" "instance_group_manager" {
name = "${var.cluster_name}"
instance_template = "${google_compute_instance_template.master_instance_template.self_link}"
base_instance_name = "${var.cluster_name}"
zone = "${var.zone}"
target_size = "${var.total_nodes}"
}
Keep all the files in a single folder. Your code is ready to deploy. Let’s go one more step ahead and make Terraform module of this Terraform configuration.
module "ads-mongodb" {
source = "" //Path of the terraform directory where above files are kept
version = "0.1.0"
replicaset_name = "rs1"
cluster_name = "mongodb-cluster-1"
zone = "us-east1-b"
project = "" // mention GCP project name here
region = "us-east1"
machine_type = "f1-micro"
image_id = "projects/ubuntu-os-cloud/global/images/ubuntu-1404-trusty-v20180913"
total_nodes = "3"
service_account_email = "" # add GCP service account email Id here
}
It is always a good practice to keep your Terraform resource configuration in the Terraform module. It will not only help new users understand your script but also make it user-friendly.
Manual verification
Manual verification will help you make sure if your auto-healing setup is working properly:
- Delete one of the nodes in the replica set from MIG. Wait for a new node to come up and ssh to it.
- Login to Mongo
- Run rs.status()
You will find that the new node is added to the replica set. Congrats! This means that your MongoDB auto-healing setup is ready.


Related Blogs



