















Posted By

Databases form the backbone of most applications, and efficient query performance is essential to ensure seamless user experiences. When working with large datasets, slow queries can lead to serious performance bottlenecks. This is where PostgreSQL indexing comes into play. Indexes are one of the most effective techniques for query optimization, enabling faster data retrieval and improving application scalability.
For engineering managers and architects overseeing Python-based applications at scale, poor database indexing is one of the most common and costly performance problems — and one of the easiest to fix if caught early. Slow queries in a PostgreSQL database don't just frustrate users; they drive up cloud infrastructure costs, increase latency across dependent services, and create bottlenecks that become exponentially harder to resolve as data volumes grow. Getting your SQLAlchemy indexing strategy right during development is significantly cheaper than diagnosing and fixing query performance issues in production. The index types and patterns covered in this guide directly address the most common scenarios engineering teams encounter when scaling PostgreSQL-backed applications.
In this blog, we’ll explore how to implement PostgreSQL indexing with SQLAlchemy, Python’s popular ORM (Object Relational Mapper), and share some database indexing best practices to help you fine-tune your application’s performance.
Why does PostgreSQL indexing matter for query performance and scalability?
Indexes allow PostgreSQL to locate rows quickly without scanning entire tables. A well-designed index can significantly boost SQLAlchemy performance, particularly when handling complex queries or large volumes of data.
For instance, searching for a user by email across millions of records becomes much faster with an index. This kind of optimization is crucial in cloud-native applications, where response times and scalability directly affect reliability. For teams running PostgreSQL on managed cloud services like AWS RDS or Google Cloud SQL, query optimization through proper indexing also has a direct impact on compute costs — fewer full table scans mean lower CPU utilization and smaller instance requirements.
sqlalchemy-postgresql-specific-index-options
How do you create a basic index in PostgreSQL using SQLAlchemy?
The index=True option allows you to build an index on a specific column. It creates a B-tree index by default on the specified column. B-tree indexes are the default indexing type in PostgreSQL and are suitable for most types of queries, particularly those involving equality comparisons, range queries, and sorting.
from sqlalchemy import JSON, TIMESTAMP, Column, Index, Integer, String,
from data.modelbase import ModelBase
class Publisher(ModelBase):
__tablename__ = 'Publisher'
id = Column(
Integer,
primary_key=True,
autoincrement=True,
)
name = Column(String, nullable=False, index=True)
from sqlalchemy import Index
# Define your table model
class MyModel(Base):
__tablename__ = 'my_table'
id = Column(Integer, primary_key=True)
value = Column(Integer)
# Create a partial index on the 'value' column where 'value' is greater than 100
partial_index = Index('idx_value_gt_100', MyModel.value, postgresql_where=(MyModel.value > 100))
partial_index.create(bind=engine)
To understand how efficient backend systems support scalable cloud-native architectures, check out our article on API testing in scalable cloud-native applications.
What is a composite index in PostgreSQL and when should you use one?
In PostgreSQL, you can create indexes on multiple columns within a table. These are called multicolumn indexes. They are also sometimes referred to as composite, combined, or concatenated indexes. A multicolumn index can include up to 32 columns. This limit can be increased if you modify the pg_config_manual.h while you rebuild PostgreSQL from source code.
However, not all types of indexes support multiple columns. Only B-tree, GiST, GIN, and BRIN indexes can be used with multiple columns. To create a multicolumn index, you can specify the columns during table creation. This is typically done by adding an index definition to the __table_args__ property and listing the desired columns within it.
from sqlalchemy import JSON, TIMESTAMP, Column, Index, Integer, String,
from data.modelbase import ModelBase
import datetime
class Employee(ModelBase):
__tablename__ = 'Employee'
id = Column(Integer, primary_key=True, autoincrement=True)
last_name = Column(String, nullable=False)
first_name = Column(String, nullable=False)
birth_date = Column(String)
created_date = Column(TIMESTAMP)
__table_args__ = (
Index('my_index', "last_name", "first_name", postgresql_using="btree"),
)
Let's look at the syntax for creating a multicolumn index:
CREATE INDEX [IF NOT EXISTS] index_name ON table_name(column1, column2, ...)
In this syntax:
- Choose an index name: Use the CREATE INDEX clause followed by a descriptive name for your index. You can also use the IF NOT EXISTS option to avoid errors if the index already exists.
- Specify the table and columns: Within parentheses after the table name, list the columns you want to inclued in the index.
Order the columns by their usage in WHERE clauses. Put the most frequently used columns first, followed by less frequently used ones. This helps the PostgreSQL optimizer utilize the index efficiently for queries that target the leading columns (those listed first).
WHERE column1 = v1 AND column2 = v2 AND column3 = v3;
Or
WHERE column1 = v1 AND column2 = v2;
Or
WHERE column1 = v1;
However, it will not consider using the index in the following cases:
WHERE column3 = v3;
Or
WHERE column2 = v2 and column3 = v3;
Beyond full table coverage, PostgreSQL allows you to create partially multicolumn indexes. This means you can use a WHERE clause within the CREATE INDEX statement to limit the data included in the index based on a specific condition.
When comparing a composite index vs a partial index in PostgreSQL, the right choice depends on your query patterns. Composite indexes are best when multiple columns consistently appear together in WHERE clauses. Partial indexes win when you're only ever querying a known subset of rows.
For further context on how optimized database access enhances performance in microservices, see our post on Java-based microservices with Micronaut.
What is a covering index in PostgreSQL and how does it speed up queries?
A covering index, also known as a "index with included columns," is an index that includes not only the columns being indexed but also additional columns. These additional columns are included in the index to cover queries, meaning that the index can satisfy a query's requirements without needing to access the actual table data.
The postgresql_include option renders INCLUDE(colname) for the given string names:
Index("my_index", table.c.x, postgresql_include=['y'])
It would render the index as CREATE INDEX my_index ON table (x) INCLUDE (y)
Note that this feature requires PostgreSQL 11 or later.
To understand how a covering index works, let's consider a scenario where you have a table with columns A, B, and C, and you frequently run a query that selects columns A and B.
Without a covering index, when you run a query like:
SELECT A, B FROM my_table WHERE C = 'some_value';
The database engine will undergo these steps:
- Look up the rows in the index on column C to find the corresponding row identifiers (such as row numbers or pointers).
- Retrieve the actual rows from the table using the row identifiers obtained from the index.
- Extract columns A and B from the retrieved rows.
However, if you create a covering index that includes columns A and B, like this:
CREATE INDEX my_covering_index ON my_table (C) INCLUDE (A, B);
Now, when you run the same query:
SELECT A, B FROM my_table WHERE C = 'some_value';
The database engine can:
- Look up the rows in the index on column C to find the corresponding row identifiers.
- Retrieve columns A and B directly from the covering index without needing to access the actual table data.
By including columns A and B in the covering index, the database avoids the extra step of accessing the table data, resulting in faster query execution.
In summary, a covering index enhances query performance by including additional columns in the index, thereby allowing the index to satisfy query requirements without accessing the actual table data. This can lead to significant performance improvements, especially for queries that frequently access specific columns.
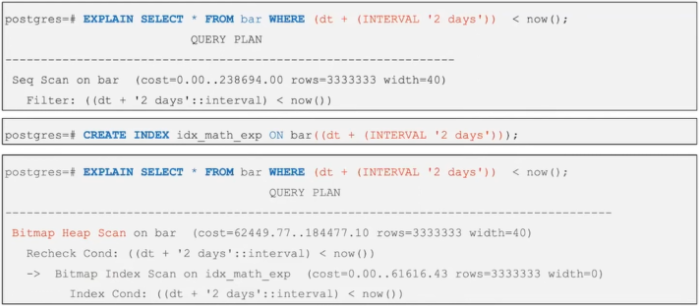
When should you use an expression index in PostgreSQL?
Let's explore the basic syntax for creating an index based on an expression:
CREATE INDEX index_name ON table_name (expression);
In this statement:
- Use CREATE INDEX followed by a descriptive name.
- Within the ON clause, construct an expression that involves columns from the target table (table_name)
PostgreSQL leverages expression indexes when the expression is used in the WHERE or ORDER BY clauses of your queries.
from sqlalchemy import Index, func
class Album(Base):
__tablename__ = 'my_table'
id = Column(Integer, primary_key=True)
name = Column(Integer)
__table_args__ = (
Index(
"idx_ex_album_name_key",
func.lower(name),
postgresql_using="gist",
postgresql_ops={"lower(name)": "gist_trgm_ops"},
),
)
Expression indexes come with a performance cost. During insert and update operations, PostgreSQL needs to evaluate the expression for each row affected. This extra processing adds overhead to these operations.
Therefore, prioritize expression indexes for queries where retrieval speed is critical, but updates and insertions are less frequent. This trade-off is worth understanding at the architecture level. If your application is write-heavy, overusing expression indexes can degrade insert and update performance noticeably in high-throughput scenarios.

How does a partial index in PostgreSQL save space and improve performance?
Partial indexes only index a subset of rows based on a condition, which can save space and improve performance for specific queries.
from sqlalchemy import Index
# Define your table model
class MyModel(Base):
__tablename__ = 'my_table'
id = Column(Integer, primary_key=True)
value = Column(Integer)
__table_args__ = (
Index('idx_value_gt_100', "value" , postgresql_where=(value > 100))
)

What are the top PostgreSQL index types and which one fits your use case?
PostgreSQL supports several types of indexes, each optimized for different types of queries:
- B-Tree Index: The default index type, suitable for most queries.

- Hash Index: Efficient for equality comparisons.

- BRIN Index: Useful for very large tables with naturally sorted data.



- GIN Index: Ideal for full-text search and JSONB data

- GiST Index: Supports various search algorithms, useful for geometric data.

What are the best PostgreSQL indexing strategies for SQLAlchemy applications?
Indexing is a critical component of database performance optimization, and PostgreSQL, coupled with SQLAlchemy, offers a robust set of tools for creating and managing indexes. By understanding and utilizing various types of indexes, such as single-column indexes, multi-column indexes, covering indexes, composite indexes, expression indexes, and partial indexes, you can significantly enhance the efficiency of your queries.
Using index=True in SQLAlchemy is a straightforward way to create B-tree indexes on specific columns, ensuring fast access and retrieval of data. For more complex indexing needs, SQLAlchemy provides options to define indexes after table creation, use covering indexes, and create indexes based on expressions or partial conditions.
Database indexing improvements must integrate smoothly into CI/CD workflows. Explore our CI/CD service to learn how we ensure database performance at scale.
By carefully selecting and implementing the appropriate index types for your database schema, you can ensure that your PostgreSQL database performs optimally, providing quick and efficient data retrieval that scales with your application's needs. Pairing strong PostgreSQL indexing with a well-structured SQLAlchemy ORM layer gives your engineering team the best foundation for building Python applications that stay fast as data volumes scale into the tens of millions of rows.
Need help optimizing PostgreSQL performance at scale?
If you’re looking for hands-on support with PostgreSQL indexing, SQLAlchemy optimization, or production performance tuning, reach out to our team and talk to PostgreSQL experts who deal with these problems every day.


Related Blogs



